PPG Attention Mechanisms and Transformer Architectures for Cardiac Signal Processing
How attention mechanisms and transformer architectures process PPG signals for heart rate, HRV, and arrhythmia detection with self-attention and positional encoding.
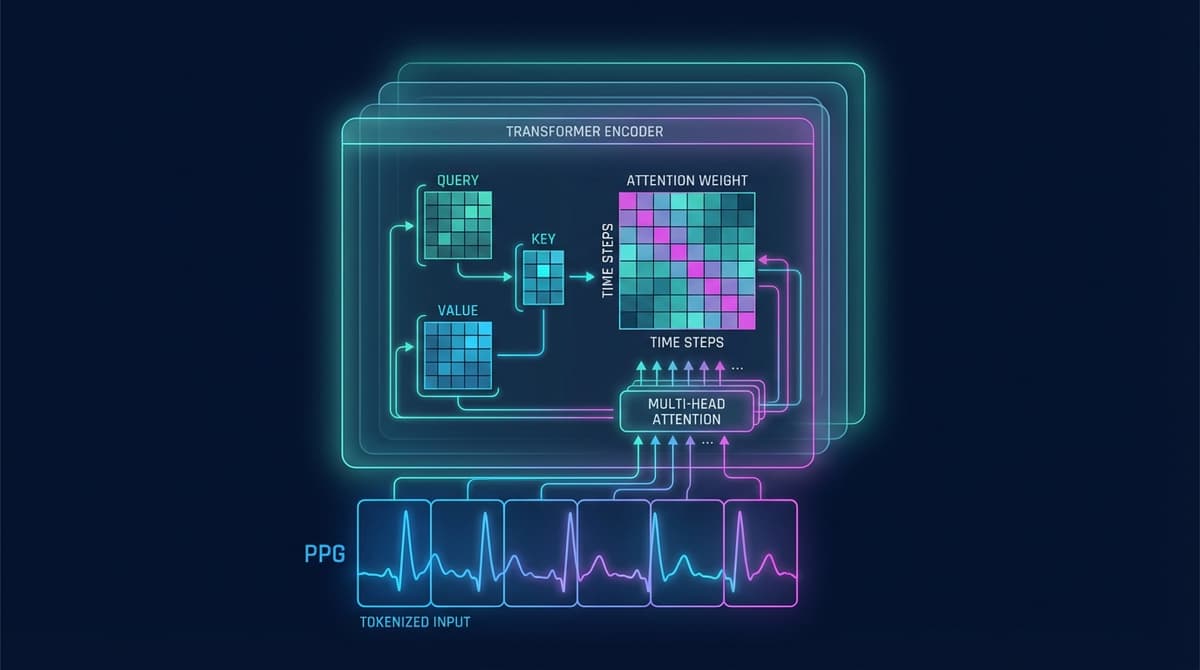
Transformer architectures process PPG signals by applying self-attention across overlapping waveform segments, allowing the model to learn which parts of the signal are most informative for a given task. Unlike convolutional or recurrent approaches that process data locally or sequentially, a transformer can directly compare any two positions in a PPG sequence in a single pass. This makes them well-suited to cardiac signal analysis, where short-term beat morphology and long-range rhythm patterns both carry diagnostic information.
Why Transformers for PPG
PPG signals contain layered structure. A single cardiac cycle lasts roughly 0.6 to 1.0 seconds at rest, but clinically meaningful patterns like atrial fibrillation or HRV trends emerge over seconds to minutes. Traditional signal processing methods handle these scales separately. CNNs extract local features well but struggle with long-range dependencies without very deep architectures. LSTMs can model sequences over time but tend to forget distant context as sequences grow long.
Attention mechanisms address this directly. By computing a weighted relationship between every position in a sequence and every other position, the model learns dependencies regardless of how far apart they are in time. For PPG analysis, this means a transformer can simultaneously attend to the diastolic notch of one beat while considering the inter-beat interval ten seconds earlier.
This architectural flexibility explains why transformer-based models have outperformed earlier deep learning approaches on several cardiac monitoring benchmarks, particularly for tasks requiring integration of both local waveform shape and global rhythm context.
Self-Attention in Cardiac Signal Analysis
Self-attention is the core operation inside a transformer block. Given a sequence of input vectors (each representing a segment of the PPG signal), the mechanism computes three matrices: queries (Q), keys (K), and values (V). The attention score between position i and position j is calculated as the dot product of their query and key vectors, scaled by the square root of the dimension size, then passed through a softmax function. The output at each position is the weighted sum of all value vectors.
For PPG signals, this has a concrete interpretation. Imagine the model is trying to characterize a beat at time t. The query at t attends to keys at all other positions. If the signal 0.8 seconds earlier contains a morphologically similar beat, that position receives high attention weight and its value contributes to the output representation. If a distant segment is a motion artifact or noise burst, it receives low weight.
This selective focus is particularly valuable for heart rate variability analysis, where the precise timing of R-wave equivalents (the systolic peaks in PPG) across dozens of consecutive beats determines the HRV metric. Models must learn to identify peaks reliably across varying morphology, and self-attention gives them the receptive field to do so without requiring handcrafted peak detection.
Research by Natarajan et al. demonstrated that attention-based models significantly improved PPG-based AF detection compared to convolutional baselines, with the attention weights visually highlighting irregular R-R intervals as the discriminative features (https://doi.org/10.1016/j.compbiomed.2020.103950).
Multi-Head Attention for Parallel Feature Extraction
A single attention head captures one type of relationship between positions. Multi-head attention runs several attention operations in parallel, each initialized differently and allowed to specialize. The outputs are concatenated and linearly projected back to the original dimension.
In practice, heads tend to learn complementary features. For PPG:
- Some heads attend to beat-to-beat interval patterns (rhythm)
- Others focus on within-beat morphology (waveform shape)
- Others may learn to suppress motion artifact by down-weighting segments with high-frequency noise
This parallelism is one reason multi-head attention tends to generalize better than single-head variants. The model is not forced to compress all relevant signal information through a single attention bottleneck. For tasks like simultaneous heart rate and blood oxygen estimation, different heads can implicitly specialize for each output.
Typically, PPG transformer models use 4 to 12 attention heads per layer. Fewer heads reduce computational cost; more heads allow finer specialization, though with diminishing returns past a certain model size.
Positional Encoding for Time-Series PPG
Transformers are permutation-invariant by design: the self-attention operation treats the input as a set, not a sequence. For time-series data like PPG, temporal order carries essential information. A beat at position 5 followed by a long pause then position 6 is physiologically different from the reverse, even if the individual beat shapes are identical.
Positional encodings inject temporal information back into the model. The original transformer paper introduced fixed sinusoidal encodings, where each position is assigned a unique vector of sine and cosine values at different frequencies. These are added to the token embeddings before the first attention layer.
For PPG specifically, two refinements are common:
Learned positional embeddings: Instead of fixed sinusoids, the model learns a separate embedding for each position during training. This works well for fixed-length input windows (e.g., always 30 seconds at 125 Hz = 3750 samples) and can adapt to the typical frequency content of PPG.
Relative positional encodings: Rather than encoding absolute position, these methods encode the distance between two positions. This is useful when inference windows vary in length or when the model needs to generalize to longer sequences than seen during training. Methods like rotary position embedding (RoPE) and ALiBi have been adapted for biosignal transformers with good results.
The choice of positional encoding has measurable impact on downstream performance, particularly for HRV tasks where timing precision matters more than morphological classification.
Key Architectures and Research
PPGFormer
PPGFormer is a transformer architecture designed specifically for remote photoplethysmography (rPPG), where the signal is extracted from facial video rather than a contact sensor. The model tokenizes short overlapping windows of the estimated PPG trace and applies a standard multi-head self-attention encoder. By attending across the full video sequence, it achieves more robust heart rate estimation under realistic conditions including head movement and lighting variation. The architecture demonstrated state-of-the-art performance on the MAHNOB-HCI and COHFACE datasets.
CardioFormer
CardioFormer adapts the Vision Transformer (ViT) framework to 1D cardiac signals including PPG. Input segments are treated analogously to image patches: fixed-length windows are linearly embedded and fed as token sequences. A classification token (CLS) prepended to the sequence aggregates global information for downstream tasks. CardioFormer has been applied to arrhythmia classification using PPG signals from wrist wearables, showing competitive performance with ECG-based transformer models on held-out subjects.
Attention-Based AF Detection
Atrial fibrillation detection from wrist PPG has attracted significant research attention because wearables provide continuous monitoring that clinical ECG cannot. Several groups have published transformer and attention-based models for this task. A notable contribution by Hannun et al. (originally for ECG but widely adapted to PPG) showed that deep neural networks with attention readout could match or exceed cardiologist-level accuracy for arrhythmia detection (https://doi.org/10.1038/s41591-018-0268-3). Subsequent work adapted these ideas to PPG signals with modifications to account for the noisier and lower-resolution nature of optical sensing.
For a broader overview of how deep learning applies to PPG analysis beyond transformers, see our guide on PPG deep learning for heart rate.
Comparison with CNN and LSTM Approaches
Understanding where transformers fit requires seeing how they compare to the architectures they are often used alongside or replacing.
CNNs
Convolutional neural networks apply fixed-size filters across the signal, making them efficient at extracting local patterns. A 1D CNN trained on PPG can learn to detect systolic peaks, diastolic notches, and the characteristic shape of the dicrotic notch. However, the receptive field of a CNN grows only as you stack more layers. Capturing a 30-second HRV sequence with single-sample resolution requires either very deep networks or pooling operations that sacrifice temporal precision.
Transformers bypass this by attending globally from the first layer. In practice, many competitive models use a CNN front-end to extract local features and then feed those features as tokens into a transformer encoder, getting the best of both approaches.
For more on convolutional approaches to PPG, see PPG convolutional neural networks.
LSTMs and Recurrent Networks
Long short-term memory networks process sequences step by step, maintaining a hidden state that theoretically carries information from earlier timesteps. In practice, LSTMs struggle with sequences longer than a few hundred steps because gradients become unstable and useful early information gets overwritten.
PPG sequences sampled at 100 Hz over 30 seconds contain 3000 samples. Processing these directly with an LSTM is computationally expensive and empirically unreliable for tasks requiring attention to early and late parts of the sequence simultaneously. Bidirectional LSTMs help but still face the fundamental bottleneck of compressing all past information into a fixed-size hidden state.
Transformers handle this by attending directly to any past position without compression. They are not strictly better than LSTMs on all tasks (LSTMs can be more sample-efficient on smaller datasets) but they scale better and generalize more reliably on larger PPG corpora.
Our article on PPG recurrent neural networks covers LSTM architectures in depth for readers interested in that comparison.
Practical Implementation Considerations
Input Tokenization of PPG Segments
Raw PPG signals are not directly fed to transformers sample by sample. At 128 Hz, even a 10-second window is 1280 samples, and the quadratic cost of self-attention (attention between all pairs of positions) makes processing at full resolution expensive.
Common tokenization strategies:
- Fixed-length windows: The signal is split into non-overlapping or overlapping segments of 16 to 64 samples. Each segment is linearly projected to the model's embedding dimension. Overlapping windows (with 50% stride) preserve more temporal continuity at the boundary.
- Learnable patch embeddings: A 1D convolutional layer with stride equal to the patch size acts as the tokenizer, simultaneously downsampling and embedding.
- Beat-synchronous tokens: Peaks are first detected with a lightweight algorithm, and each beat is warped to a fixed length before embedding. This aligns tokens with physiological units rather than arbitrary time windows.
The tokenization choice affects what information is available at each position and therefore what patterns attention can learn.
Sequence Length Tradeoffs
Transformer attention scales as O(n²) in both time and memory, where n is the sequence length (number of tokens). A 30-second window at 128 Hz with 32-sample patches produces ~120 tokens, which is tractable on standard hardware. Extending to 5-minute windows for HRV analysis pushes to ~1200 tokens, roughly 100x the attention computation.
Efficient attention variants address this. Sparse attention (attending only to nearby and a few global tokens), linear attention approximations, and sliding-window attention all reduce complexity while preserving most of the modeling capacity. For most clinical PPG applications, 30-second to 2-minute windows strike a good balance between HRV context and computational cost.
Computational Cost and Deployment
Training transformer-based PPG models requires GPU resources, but inference can often be optimized for embedded deployment. Quantization (converting float32 weights to int8), attention head pruning, and knowledge distillation from a large transformer to a smaller student model are all practical paths to deploying these models on wearable processors.
For remote PPG applications running on smartphones, the camera capture and signal extraction pipeline typically dominate latency, making the transformer inference cost secondary. See our overview of PPG transformer models for architecture-specific benchmarks.
FAQ
What is an attention mechanism in the context of PPG signals?
An attention mechanism is a learned function that decides how much weight to give each part of the input when producing an output. For PPG signals, it allows a model to focus on the most relevant portions of the waveform, such as systolic peaks or irregular inter-beat intervals, when making predictions about heart rate, HRV, or arrhythmia.
How does a transformer differ from a CNN for PPG analysis?
A CNN applies local filters and builds up a limited receptive field through stacking layers. A transformer attends globally from the first layer, comparing every segment of the PPG signal to every other segment simultaneously. Transformers generally outperform CNNs on tasks requiring long-range temporal reasoning, while CNNs are more efficient for local feature detection.
What is positional encoding and why does PPG need it?
Positional encoding adds temporal order information to the input tokens before they enter the transformer. Without it, the model would treat the PPG sequence as an unordered set and lose all timing information. For cardiac signals, timing is fundamental to beat detection, HRV, and rhythm classification.
Can transformers detect atrial fibrillation from PPG?
Yes. Several published models use attention-based architectures to detect AF from wrist PPG. They learn to identify the irregular R-R intervals and loss of discrete pulse peaks that characterize AF. Performance on consumer wearable data is variable but competitive with traditional algorithmic approaches, particularly in ambulatory settings.
What sequence length is best for PPG transformer models?
This depends on the task. Heart rate estimation from clean signals can work with 10 to 30-second windows. HRV analysis typically requires at least 60 seconds, and ideally 5 minutes, to compute standard frequency-domain metrics. AF detection benefits from longer windows to observe rhythm irregularity across many beats. Longer windows increase computational cost due to the quadratic scaling of standard attention.
What is multi-head attention and does it help for PPG?
Multi-head attention runs several independent attention operations in parallel and concatenates their outputs. Each head can specialize in different aspects of the signal, such as beat morphology, rhythm pattern, or noise characteristics. For PPG this is beneficial because the signal carries overlapping sources of information that are not easily separated by a single attention mechanism.
How are PPG signals tokenized for transformer input?
Raw PPG samples are grouped into short segments (typically 16 to 64 samples per token) and linearly projected into the model's embedding space. Some models use convolutional layers as the tokenizer to extract richer local features before the attention layers. Beat-synchronous tokenization, which aligns tokens to individual cardiac cycles, is an alternative that matches tokens to physiological units.